

[核心提示] 读项亮的《推荐系统实践》后总结所得:算法虽然不能解决全部问题,但算法可以变得更人性化。网络就是社会,其实算法和人之间早已不那么泾渭分明了。
 微信扫一扫,分享文章
微信扫一扫,分享文章推荐系统这个东西其实在我们的生活中无处不在,比如我早上买包子的时候,老板就经常问我要不要来杯豆浆,这就是一种简单的推荐。随着互联网的发展,把线下的这种模式搬到线上成了大势所趋,它大大扩展了推荐系统的应用:亚马逊的商品推荐,Facebook的好友推荐,Digg的文章推荐,豆瓣的豆瓣猜,Last.fm和豆瓣FM的音乐推荐,Gmail里的广告......在如今互联网信息过载的情况下,信息消费者想方便地找到自己感兴趣的内容,信息生产者则想将自己的内容推送到最合适的目标用户那儿。而推荐系统正是要充当这两者的中介,一箭双雕解决这两个难题。
推荐系统的评判标准
首先我们得明确什么是好的推荐系统。可以通过如下几个标准来判定。
- 用户满意度 描述用户对推荐结果的满意程度,这是推荐系统最重要的指标。一般通过对用户进行问卷或者监测用户线上行为数据获得。
- 预测准确度 描述推荐系统预测用户行为的能力。一般通过离线数据集上算法给出的推荐列表和用户行为的重合率来计算。重合率越大则准确率越高。
- 覆盖率 描述推荐系统对物品长尾的发掘能力。一般通过所有推荐物品占总物品的比例和所有物品被推荐的概率分布来计算。比例越大,概率分布越均匀则覆盖率越大。
- 多样性 描述推荐系统中推荐结果能否覆盖用户不同的兴趣领域。一般通过推荐列表中物品两两之间不相似性来计算,物品之间越不相似则多样性越好。
- 新颖性 如果用户没有听说过推荐列表中的大部分物品,则说明该推荐系统的新颖性较好。可以通过推荐结果的平均流行度和对用户进行问卷来获得。
- 惊喜度 如果推荐结果和用户的历史兴趣不相似,但让用户很满意,则可以说这是一个让用户惊喜的推荐。可以定性地通过推荐结果与用户历史兴趣的相似度和用户满意度来衡量。
简而言之,一个好的推荐系统就是在推荐准确的基础上,给所有用户推荐的物品尽量广泛(挖掘长尾),给单个用户推荐的物品尽量覆盖多个类别,同时不要给用户推荐太多热门物品,最牛逼的则是能让用户看到推荐后有种「相见恨晚」的感觉。
推荐系统的分类
推荐系统是建立在大量有效数据之上的,背后的算法思想有很多种,要大体分类的话可以从处理的数据入手。
1.利用用户行为数据
互联网上的用户行为千千万万,从简单的网页浏览到复杂的评价,下单......这其中蕴含了大量的用户反馈信息,通过对这些行为的分析,我们便能推知用户的兴趣喜好。而这其中最基础的就是「协同过滤算法」。
「协同过滤算法」也分两种,基于用户(UserCF)和基于物品(ItemCF)。所谓基于用户,就是跟据用户对物品的行为,找出兴趣爱好相似的一些用户,将其中一个用户喜欢的东西推荐给另一个用户。举个例子,老张喜欢看的书有A,B,C,D;老王喜欢看的书有A,B,C,E。通过这些数据我们可以判断老张和老王的口味略相似,于是给老张推荐E这本书,同时给老王推荐D这本书。对应的,基于物品就是先找出相似的物品。怎么找呢?也是看用户的喜好,如果同时喜欢两个物品的人比较多的话,就可以认为这两个物品相似。最后就只要给用户推荐和他原有喜好类似的物品就成。举例来说,我们发现喜欢看《从一到无穷大》的人大都喜欢看《什么是数学》,那如果你刚津津有味地看完《从一到无穷大》,我们就可以立马给你推荐《什么是数学》。
至于什么时候用UserCF,什么时候用ItemCF,这都要视情况而定。一般来说,UserCF更接近于社会化推荐,适用于用户少,物品多,时效性较强的场合,比如Digg的文章推荐;而ItemCF则更接近个性化推荐,适用于用户多,物品少的场合,比如豆瓣的豆瓣猜、豆瓣FM,同时ItemCF还可以给出靠谱的推荐理由,例如豆瓣的「喜欢OO的人也喜欢XX」和亚马逊的「买了XX的人也买了OO」。

协同过滤算法也有不少缺点,最明显的一个就是热门物品的干扰。举个例子,协同过滤算法经常会导致两个不同领域的最热门物品之间具有较高的相似度,这样很可能会给喜欢《算法导论》的同学推荐《哈利波特》,显然,这不科学!要避免这种情况就得从物品的内容数据入手了,后文提到的内容过滤算法就是其中一种。
除了协同过滤算法,还有隐语义模型(LFM)应用得也比较多,它基于用户行为对物品进行自动聚类,从而将物品按照多个维度,多个粒度分门别类。然后根据用户喜欢的物品类别进行推荐。这种基于机器学习的方法在很多指标上优于协同过滤,但性能上不太给力,一般可以先通过其他算法得出推荐列表,再由LFM进行优化。
2.利用用户标签数据
我们知道很多网站在处理物品条目的时候会通过用户自己标注的标签来进行分类,比如网页书签Delicious,博客的标签云,豆瓣书影音的标签。这些标签本身就是用户对物品的一种聚类,以此作为推荐系统的依据还是很有效的。
关于标签的推荐,一种是根据用户打标签的行为为其推荐物品,还有一种是在用户给物品打标签的时候为其推荐合适的标签。
根据标签推荐物品的基本思想就是找到用户常用的一些标签,然后找到具有这些标签的热门物品,将其推荐给用户。这里要注意两个问题,一个是要保证新颖性和多样性,可以用TF-IDF方法来降低热门物品的权重;另一个则是需要清除某些同义重复标签和没有意义的标签。
在用户打标签时为其推荐标签也是相当重要的,一方面能方便用户输入标签,一方面能提高标签质量,减少冗余。典型的应用场景就是用豆瓣标记书影音。这里的思想就是将当前物品上最热门的标签和用户自己最常用的标签综合在一起推荐给用户。其实豆瓣就是这么做的,它在用户标记物品的时候,给用户推荐的标签就分为「我的标签」和「常用标签」两类,而在「我的标签」里也考虑了物品的因素。
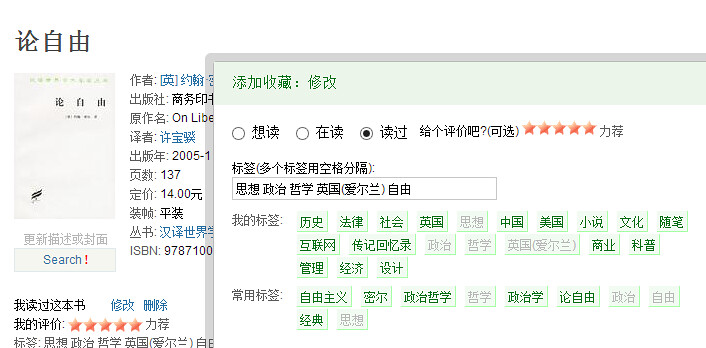
基于标签的推荐有很多优点,一方面可以给用户提供比较准确的推荐理由;另一方面标签云的形式也提高了推荐的多样性,给了用户一定的自主选择。标签其实可以看做一种物品的内容数据,比如书的作者,出版社,类型;音乐的国别,风格,作者等等,基于这些信息的推荐可以弥补上述基于用户行为推荐的一些弱点。
3.利用上下文信息
此处所谓的上下文,是指用户所处的时间,地点,心情等。这些因素对于推荐也是至关重要的,比如听歌的心情,商品的季节性等等。
这里主要以时间为例说说,在很多新闻资讯类网站中,时效性是很重要的一点,你要推荐一篇一年前的新闻给用户,估计会被骂死。在这种推荐中就需要加入时间衰减因子,对于越久之前的物品,赋予越小的权重。同样的思想也可以用在基于用户行为的推荐中,这里有很多可以优化的地方。对于ItemCF来说,同一用户在间隔很短的时间内喜欢的不同物品可以给予更高的相似度,而在找相似物品时也可以着重考虑用户最近喜欢的物品;对于UserCF,如果两个用户同时喜欢了相同的物品,那么可以给予这两个用户更高的相似度,而在推荐物品时,也可着重推荐口味相近的用户最近喜欢的物品。我们可以给相似度和用户的行为赋予一定权重,时间间隔越久权重越低,经过这种改进的「协同过滤算法」往往能得到用户更满意的结果。
类似的,在LBS成为应用标配的今天,可以根据物品与用户的距离赋予相应的权重,再综合其他因素得到靠谱的地点推荐。
4.利用社交网络数据
如今以Facebook,Twitter为首的社交网络大行其道,而其中的海量数据也是一大宝库。实验证明,由于信任的作用,来自好友的推荐往往能获取更高的点击率,鉴于此,亚马逊就利用了Facebook的信息给用户推荐好友喜欢的商品。此种推荐类似于UserCF,只是寻找用户之间的关系时除了兴趣相似度以外还得考虑熟悉度(如共同好友个数),这样一来,你的闺蜜们和基友们喜欢的物品很可能就会被推荐给你。
在社交网络内部也有许多推荐算法的应用。其中最重要的当属好友推荐,可依据的数据有很多:人口统计学属性(例如人人的找同学),共同兴趣(如Twitter中转发的信息),好友关系(共同好友数量,N度人脉)。另外还有信息流(Timeline)推荐,这其中以Facebook的EdgeRank为代表,大致思想就是:如果一个会话(Feed)被你熟悉的好友最近产生过重要的行为,它在信息流的排序中就会有比较高的权重。另外,基于社交网络兴趣图谱和社会图谱的精准广告投放也是推荐系统的关键应用,它决定着社交网站的变现能力。
推荐系统的冷启动问题
介绍了这么多类的推荐系统,最后说说推荐系统的一个主要问题:冷启动问题。具体分三种情况:如何给新用户做个性化推荐,如何将新物品推荐给用户,新网站在数据稀少的情况下如何做个性化推荐。
对此也有相应的解决方案。对于新用户,首先可以根据其注册信息进行粗粒度的推荐,如年龄,性别,爱好等。另外也可以在新用户注册后为其提供一些内容,让他们反馈对这些内容的兴趣,再根据这些数据来进行推荐。这些内容需要同时满足热门和多样的要求。而对于新物品的推荐,可能就要从其内容数据上下功夫了。我们可以通过语义分析对物品抽取关键词并赋予权重,这种内容特征类似一个向量,通过向量之间的余弦相似度便可得出物品之间的相似度,从而进行推荐。这种内容过滤算法在物品(内容)更新较快的服务中得到大量应用,如新闻资讯类的个性化推荐。
而在网站初建,数据不够多的情况下,可能就要先通过人工的力量来建立早期的推荐系统了。简单一点的,人工编辑热门榜单,高级一点的,人工分类标注。国外的个性化音乐电台Pandora就雇了一批懂计算机的音乐人来给大量音乐进行多维度标注,称之为音乐基因。有了这些初始数据,就可以方便地进行推荐了。国内的Jing.fm初期也是通过对音乐的物理信息,情感信息,社会信息进行人工分类,而后再通过机器学习和推荐算法不断完善,打造出了不一样的个性化电台。
除了这些,利用社交网络平台已有的大量数据也是一个不错的方法,尤其是那些依托于其他SNS账号系统的服务。
算法vs人
有很多人怀疑推荐系统是否会让一个人关注的东西越来越局限,但看完这些你会觉得并非如此,多样性,新颖性和惊喜度也都是考察推荐系统的要素。而至于算法和人究竟哪个更重要的争论,我很赞同唐茶创始人李如一的一个观点:
在技术社群的讨论里,大家默认觉得让推荐算法变得更聪明、让软件变得更「智能」一定是好事。但人不能那么懒的。连「发现自己可能感兴趣的内容」这件事都要交给机器做吗?不要觉得我是Luddite。真正的技术主义者永远会把人放到第一位。
我想补充的是,算法虽然不能解决全部问题,但算法可以变得更人性化。套用某人「网络就是社会」的论断,其实算法和人之间早已不那么泾渭分明了。
头图来源:Dribbble




已有7条回复我要回复
没太明白,但觉得说的很透彻
谢谢分享,但是有个关于热门物品的问题,“协同过滤算法也有不少缺点,最明显的一个就是热门物品的干扰。”两个不同领域的热门物品之间怎么可能有高的相似度呢?因为是两个不同领域的物品,所以他们的交集用户肯定不会多,没有交集自然不能算相似度,所以距离不可能近?请解释